本文共1257个字
导包
scrapy是使用redis这个数据库实现分布式的,因此我们刚开始要安装这个scrapy-redis包。pip install scrapy-redis。
创建项目
创建项目:scrapy startproject base_scrapy_plus(⚠️这个项目名不能包含中文,不然会报错)
移动到命令执行目录:cd base_scrapy_plus
生成爬虫:scrapy genspider -t crawl blogspider bugdesigner.cn
配置settings文件
一共需要配置的地方有三个
配置队列:
'scrapy_redis.pipelines.RedisPipeline': 800 #开启管道,优先级给高一点
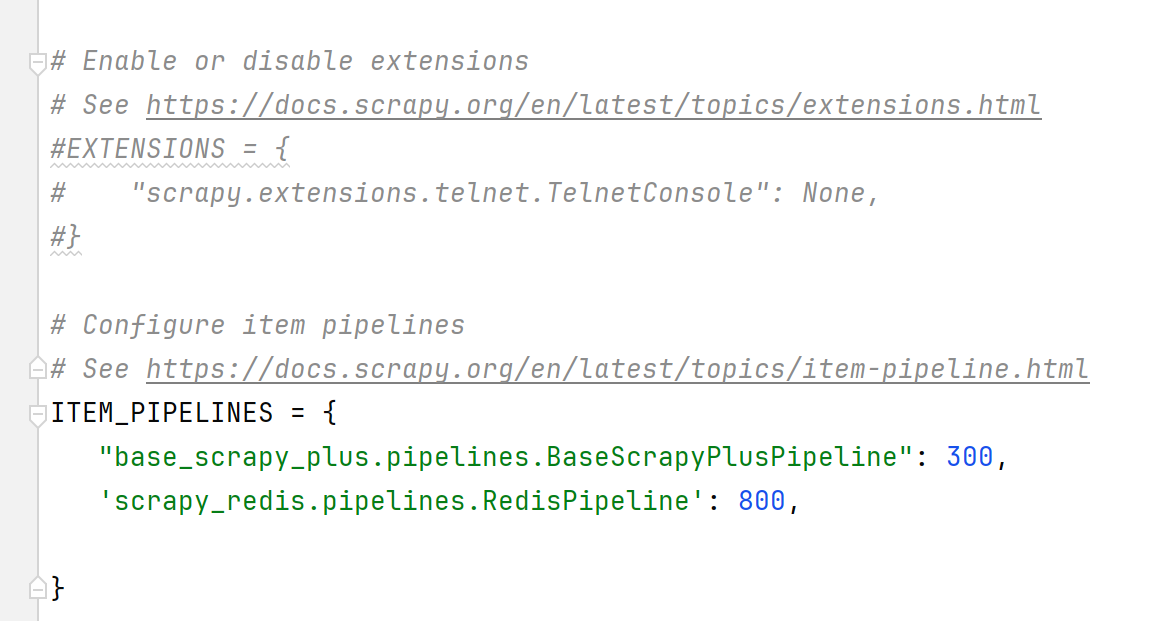
配置分布式
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #去重
SCHEDULER = "scrapy_redis.scheduler.Scheduler" #开启调度器
SCHEDULER_PERSIST = True #做持久化
配置Redis数据库信息
REDIS_HOST = "192.168.182.100" #远程redis主机地址
REDIS_PORT = 6380 #端口
REDIS_PARAMS = {'password': '123456'} #redis的配置参数,这里是配置密码
spider配置
spider里面需要做的工作有两个
1:指定redis中list的key。redis_key = 'blogQuene' 这样使用lpush blogQuene "https://www.bugdesigner.cn"就可以启动分布式爬取了
2:继承RedisCrawlSpider这个类,这个类导入命令为from scrapy_redis.spiders import RedisCrawlSpider
❗parse方法不要再实现了,如果spider里面自己实现会重写继承的这个类里面的parse
剩下的就跟正常的CrawlSpider全站爬取一样了。scrapy-redis支持增量爬取,如果有其他的url,使用lpush命令添加即可。不会配置redis的,请移步我的这篇文章。如果有多台机器,都连接上统一的redis数据库就可以实现分布式爬取了。
启动项目以后,正常的话是这样,爬取完毕以后等待下一个url进来然后处理

可能存在的问题
1: TypeError: ExecutionEngine.crawl() got an unexpected keyword argument 'spider'
这个问题是由于先进行的爬取,再往list里面添加url。启动顺序应该是先往redis里面的blogQuene队列里面填值 ,再使用scrapy crawl blogspider启动爬虫
这个问题网上很多人和GPT说是版本不兼容,实际上完全不是版本问题......,我猜想是因为list里面没有数据,所以读取的时候会报错。
需要博客项目分布式全站抓取演示源码移步


文章评论